

Introduction
With the emergence of tools like Google's Bard and OpenAI's ChatGPT, many people are becoming curious about how these AI tools work. In a series of posts, I aim to demystify the technology behind these AI tools by providing a peek inside them. My goal is to make these topics accessible to a wide audience, requiring only high school-level mathematics. The intended audience includes people who do not have a deep background in computer science and AI, such as CEOs, product managers, UX designers, government officials, high school students, as well as engineers and computer scientists seeking an easy introduction to the topic. The focus is on building intuition for the technology rather than providing an accurate description of the underlying tech, although any feedback on inaccuracies is welcome.
What are LLMs?
Today's post aims to demystify Large Language Models (LLMs), which are the fundamental AI models behind tools such as Bard and ChatGPT. The LLM used in Bard is known as LaMBDA, while the LLM used in ChatGPT is known as GPT (such as GPT-3 and GPT-4). Numerous other LLMs are available from various companies, as illustrated in the graphic at the end of this article. After reading this post, you will have a high-level understanding of what LLMs are capable of and develop some intuition about how they work internally at a very high level. You should be able to engage in insightful conversations with your friends and colleagues about LLMs and describe their strengths and limitations.
LLMs emerged from research in the Natural Language Processing (NLP) field, which is a branch of both linguistics and computer science. Traditionally, language modeling is defined as the task of predicting the next word in a sequence of words. You may have already seen this in action on your phone or PC, where you type in a partial sentence, and it offers you several options to complete the sentence.
To illustrate, I typed the following prompt on the public version of Bard:
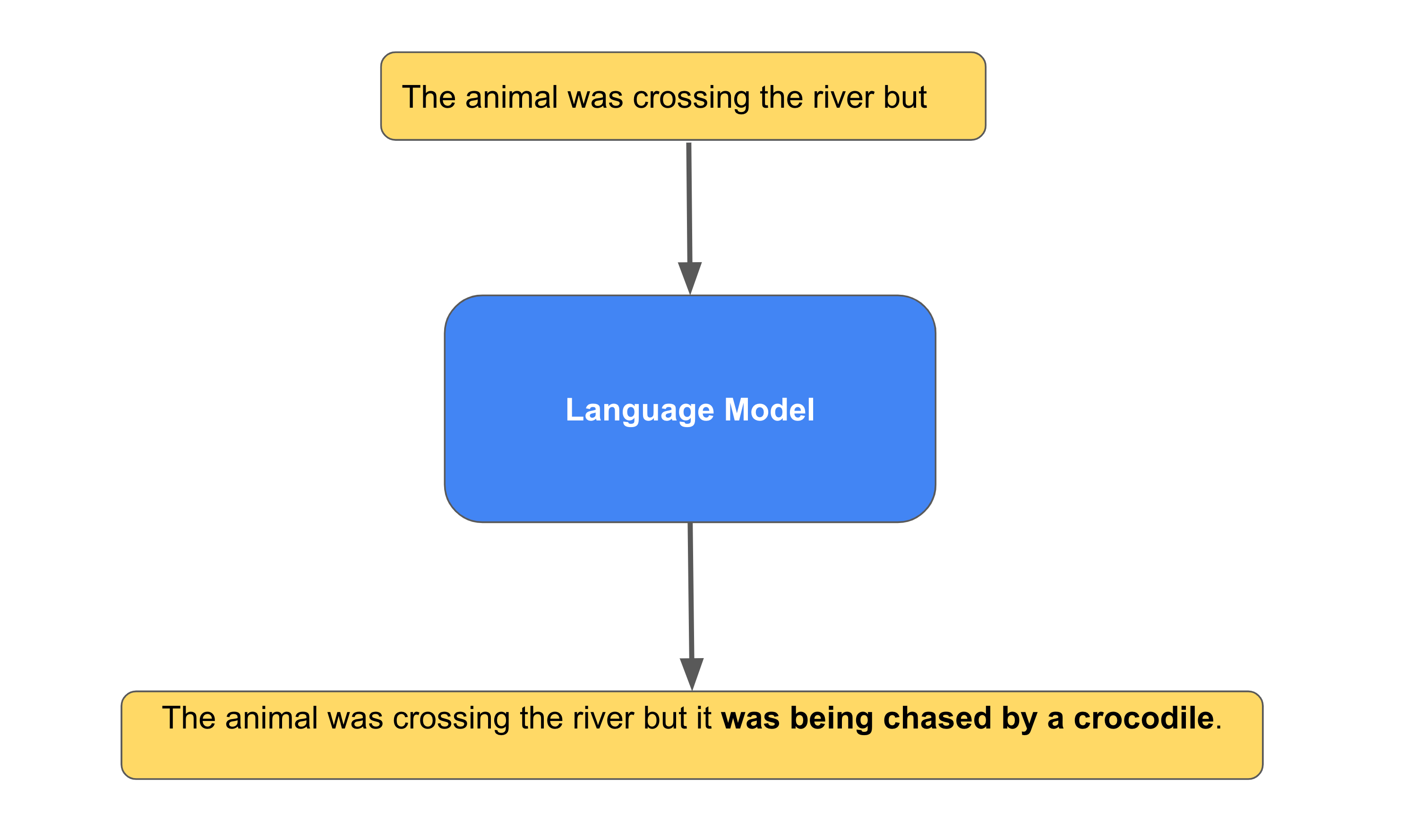
"Complete the sentence: The animal was crossing the river but it"
Bard's response was:
"The animal was crossing the river but it was being chased by a crocodile…"
Note, the word "it" in my incomplete sentence above. It could have referred to the animal or the river. In this case, Bard completed the sentence in a way that made it clear that the word "it" is referring to the animal and not the river.
I then queried,
"Complete the sentence: The animal was crossing the river but it was too wide"
I added a few more words (“was too wide”) to the sentence, hinting to Bard that "it" in the sentence refers to the river and not the animal.
Here's Bard's response after that hint:
"The animal was crossing the river but it was too wide. The animal was a small rabbit, and the river was a wide, fast-moving stream…"
Bard correctly interprets “it” as referring to the river and generates rest of the paragraph. Bard seems to understand context of words. Amazing!
For the two prompts above the corresponding text generated by ChatGPT was:
"The animal was crossing the river but it was swept away by the strong current."
“The animal was crossing the river but it was too wide for it to make it to the other side safely.”
In the last sentence, one of the “it” refers to the animal and other one to the animal.
The story above appears plausible, as if it were written by a human. However, it is generated word by word using a probabilistic model. This particular example will be valuable in future posts when we analyze how the model manages to interpret ambiguous words like "it" based on the context in the surrounding words.
How Language Models work
In this section, we will examine a conceptual view of the language models' tasks. Although this perspective does not precisely correspond to how LLMs operate today, it is critical to comprehending modern LLMs. At the heart of LLMs are algorithms that predict the probabilities of words in a dictionary that are most likely to follow a sequence of words the model has already encountered. Once the model generates the next word, it continues predicting the word that follows it, and it keeps doing so until it generates a sentence or paragraph of the desired length. Let's express this task in probabilistic terms. Even if you don't have much experience in probability, you should be able to understand it easily, so don't be too concerned.
A quick sidebar on notation for conditional probability:
P(A|B) - This is read as probability of event A happening given event B has already happened. I also like to read this notation backwards as - given B has happened what’s the probability of A happening.
e.g. P( COVID | Test Positive) - Probability the person has COVID assuming the test results were positive.
Using that notation above, the task of predicting the next word given a sequence of words can be written as:

The first equation represents the probability of wordN occurring next in the sequence of words: word0 to wordN-1.
The second equation represents our first example: "The animal was crossing the river but it." The language model thinks the probability of the word "was" occurring next in the sequence is 0.3, while the probability of the word "struggled" is 0.2. There are many other words from the dictionary that could have followed this sequence, but for brevity, we’ll skip them here.
So how does the model pick the next word to generate in the sequence?
We can sort the list of words in the dictionary in descending order of their probabilities and pick, say, the top 10 words. In this case, let’s say the words "was" and "struggled" are the top 2 words, and there are 8 other words in the top 10 list. LLMs can use various algorithms to randomly select a word from this top 10 list, ordered by their probabilities. You can always pick the top word with the highest probability, but this is likely to generate the same monotonous sentence each time. By introducing some randomness in selecting the next word, the language model generates more engaging sentences, which also explains why LLMs produce different responses when regenerating responses to the same prompt.
It is not too hard to imagine from the above illustration how machine translation from one language to another might work. Instead of generating the next word in the output, the model translates the word in the input language to a word in the output language in the response stream. Word-to-word translation isn't going to give you a coherent sentence in the output language, so the models do a lot more work than this conceptual word-to-word mapping described here.
Here's an example from ChatGPT translating the sentence above from English to Gujarati, my native language.
Prompt:
Translate to Gujarati: The animal was crossing the river but it was being chased by a crocodile
Response:
જંગલી પ્રાણી નદી પાર કરતો હતો પરંતુ એને એક મગરમાછ પીછે પાડી રહ્યો હતો. (Jangali prāṇī nadī pār karatō hatō parantu ēnē ēka magar-māch pīchē pāḍī rahyō hatō.)
The examples above provide insight into how LLMs generate sentences and paragraphs. These models are also capable of performing various other NLP tasks, such as analyzing sentiment in movie reviews or articles, identifying spam in emails, translating between languages, answering questions, generating text in the style of a particular author, or summarizing text.
The “Large” in the LLM
As mentioned earlier, you may have used language models before on your phones and PCs. However, what sets LLMs apart is that they are trained on massive amounts of text data from books, articles, Wikipedia, and other internet content. The size of these models is measured on two different axes. The first axis is the amount of text on which these AI models are trained, measured in terms of the number of tokens (similar to words, but with minor differences). The details, however, are not crucial for this post. Google Research's PaLM language model, for instance, is estimated to be trained on 780B tokens.
The second axis for measuring model size is the number of parameters that store the learned state of the model to make predictions. Parameters can be thought of as the memory required to store and encode the vast amounts of information processed by these models. Google's PaLM language model, for example, has 540B parameters.
As of April 2023, the sizes of the SOTA (State of the Art) AI models, measured in terms of the number of parameters, are illustrated in the image below from https://lifearchitect.ai/models/.
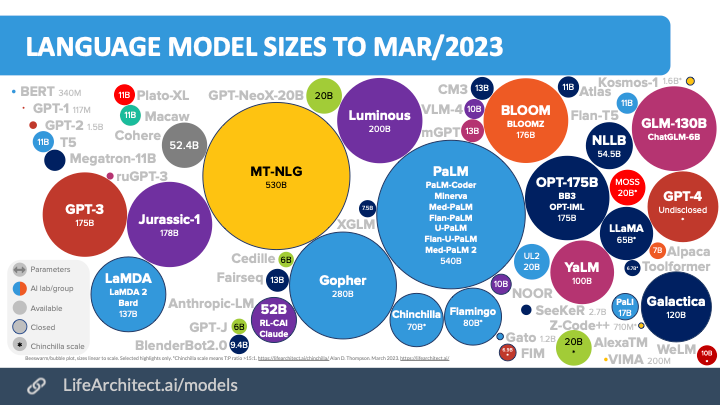
Some of these large models take months to train and require a vast amount of computational resources, costing hundreds of millions of dollars.
Limitations
By now, you may have already gathered that LLMs do not necessarily generate factually correct text. However, depending on the information they are trained on, they can provide fairly good answers to many questions. Other limitations of LLMs include their inability to perform mathematical reasoning, as they may fail on even easy problems. Additionally, many of these models are frozen in time, preventing them from answering real-time questions such as the current price of a stock or product being sold online. LLMs also suffer from bias and safety issues, which are beyond the scope of this post. Researchers worldwide are actively working to address many of these shortcomings of LLMs.
I hope this post has given you a good understanding of how LLMs work and their power and limitations. In the future, I would like to cover some of the underlying building blocks of technology that make LLMs possible. Please leave any feedback on this post in the comments below.
Bhavesh Mehta
mehtabhavesh9 at gmail dot com
P.S. This article was initially drafted by me, and then I utilized ChatGPT as my copilot to assist in rewriting paragraphs with proper grammar and punctuation for improved clarity for the readers.